Stephan Schmidt - July 9, 2022
Selfhealing Code for Startup CTOs and Solo Founders
How self-healing systems make you more productive
TL;DR: Self-healing architectures prevent small failures from cascading into major outages by automatically recovering from issues like resource spikes or connection failures, freeing solo founders and early-stage CTOs from firefighting incidents so they can focus on delivering customer value. Implement patterns like circuit breakers, automatic restarts with systemd, failover services, graceful degradation, and timeouts to reduce maintenance overhead and gain critical development time.
Solo founders and early startup CTOs have one thing in common: The lack time. Lots of it. Too many things going on everywhere.
One way to gain time is to implement a self-healing architecture. Self-healing architecture and patterns mean code that get an application working again after it stopped working. Self-healing code is different from defensive programming.
When code and systems heal themselves, there are less problems on while scaling. When I was CTO we often had scaling problems where systems would fail, and because they weren’t selfhealing, we had to restart the systems and then restart other systems which depended on the first ones. Selfhealing systems prevent incidents. A selfhealing system may reover a usage spike or resource constraints, where a normal system would lead to a site outage and an incident. Outages and crisis’ happen when smaller problems overlap. When you stand at the beach and waves splash your knees. Then waves overlap and splash your faces. Dealing with small problems is paramount so they don’t aggregate. Selfhealing systems will do that for you.
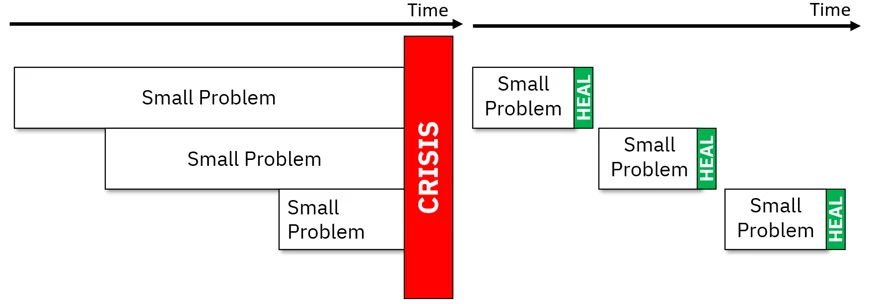
Outages and incidents are stressful and take time to fix. Time the solo founder and early startup CTO don’t have. The time they gain from self-healing systems then can be applied to delivering customer value and gain traction.
Patterns for Selfhealing
The prime example for selfhealing systems is Erlang with its runtime. Erlang uses a supervisor hierarchy to detect faulty components and restart them. But even if you don’t use Erlang, there are ways for self healing systems for every framework and programming language.
Common patterns for self-healing:
- Circuit breakers
- Restart failing components
- Failover 3rd party services
- Degraded service / E.g., Read-Only
- Timeouts
Circuit breakers
Circuit breakers are a pattern where a connection is stopped when there are too many errors. Suppose a database is overloaded with connections and queries are not going through with existing connections hanging, a circuit breaker will open and close all connections to the database. Then it will wait for some time and try to connect to the database again. This way the database gets all open connections closed and regains its health, healing. After the database has healed, the ciruit breaker will close again and reestablish connections and operations.
Restart failing programs
Not every language is Erlang. But think about the concept: Just let it crash. When using systemd on Linux you can manage restarting and readyness to accept connections with your application. When it get into a state that it can’t read a file or queries to a database are no longer working, just stop it. When it’s run with systemd the daemon will just start it again, your application will newly read the configuration and establish connections to microservices and databases. If the environment is sound again, the application will work. Systemd even supports port activation. This means systemd will own the port, e.g. port 443 for HTTPS. During the downtime of your executable systemd will cache all incoming requests and as soon as your application is ready to accept requests again, it will relay the cached ones. Customers are not impacted this way.
Have some randomness in the restart timing to prevent a stampede of servers. If all servers restart at the same second and then try to regain resources and connections at the same time, that stampede will again kill the shared resource.
Failover 3rd party services
Often third party dependecies are a reliability liability. If your payment provider is down, or their API is, then you’re company is not earning money. Depending on the business model this is harmless or crucial. Having a second option for a payment provider enables you to continue business, although your primary provider is down. This might not be driven by business (they usually swap payment providers for better terms) but needs to be driven by the CTO as a BC/DR issue.
Degraded features, e.E. Readonly-mode
If a services has depends on other systems to provide its value to customers, and those dependecies have problems, it’s often better to degrade features gracefully instead of stopping the service. Hackernews has a read-only mode for maintanance. If you’re a marketplace, a read-only mode can still provide a lot of value to customers, when your main database might be down. Or a button for the feature is removed from the website instead of a button that leads to a non-working system.
Timeouts
Everything that does IO (and even long computes) should have a timeout. A connection that is hanging and doesn’t have a timeout blocks resources and a surge of these might bring down the service. So everything needs to have a timeout. When connections time out, they will free resources so other functionality might work.
Be careful, sometimes one connection has different timeouts on different levels. Be sure to catch and sync them all, TCP/IP timeouts, HTTP connection timeouts, database connection timeouts.
Conclusion
Handholding systems, fixing outages and developing around scaling pains takes time and detracts from delivering customer value and getting traction. Self-healing systems result in less maintanance effort and therefor more time for developing features, which is crucial for solo entrepreneurs and early startup CTOs.
More Stuff from Stephan






About me: Hey, I'm Stephan, I help CTOs with Coaching, with 40+ years of software development and 25+ years of engineering management experience. I've coached and mentored 100+ CTOs and founders. I've founded 3 startups. 1 nice exit. I help CTOs and engineering leaders grow, scale their teams, gain clarity, lead with confidence and navigate the challenges of fast-growing companies.
Most of the CTOs I coach didn't know CTO coaching was a thing until they were already drowning. It is a thing - here's what it is.
