I did the best on the article but I might have made mistakes in the code or testing setup and appreciate all feedback. Code can be found on Github.
Radical Simplicity is about having the fewest systems possible and the least lines of code and configuration. This keeps maintenance costs down and makes changes cheap and easy. Radical Simplicity doesn’t mean to use Assembler code or C. So should we use SQL as the simplist thing or something different?
When writing server side code to read data from a database developers usually use either direct SQL or an ORM. The ORM saves writing SQL code but costs performance and increases the need for more classes. Direct SQL is faster and has fewer model lines of code, but is more difficult to change.
Although many developers reflex today is to go to React and a SPA with GraphQL, it is much less code to write an server side application that produces HTML. But GraphQL seems a concept that makes reading data from one or more data sources easy. So with the rise of GraphQL I’ve wondered if GraphQL would be even better than an ORM to write data views in applications. In the best case you write an HTML template and a GraphQL query without any other code.
We focus on the reading side of data, not writing it. And I would argue they can be different. Why would one use different code for reading and writing to the database? From my experience reads and writes scale differently, and while it may seem advantages to use the same code for reading and writing, it often complicates changing code. We want to see the read part of a web application can benefit from GraphQL.
As an example we use a simple Task app, with Tasks that have a User attached and a Status. We implement a page that displays all Tasks for one user with the User and the Status.
Lets evaluate how to use GraphQL to render server side HTML templates. We compare a GraphQL solution to bare-bones SQL and to an ORM. I use Golang with Graphjin for GraphQL, GORM for the ORM and PGX for the bare-bones SQL solution.
SQL
The SQL to create the database is
CREATE TABLE users(
id BIGINT unique PRIMARY KEY,
name TEXT
);
CREATE TABLE status (
id INT unique,
status TEXT
);
CREATE TABLE tasks (
id BIGINT PRIMARY KEY,
title TEXT,
user_id bigint REFERENCES users(id),
status_id INT REFERENCES status(id)
);
SQL with PGX
We start of by writing the simple SQL solution. for that we use PGX as a Golang library.
We need a model to put data into which we hand over to the HTML template. The model is simply the data from the tasks.
type PgxTaskList struct {
Tasks []PgxTask
}
type PgxTask struct {
Id int64
Title string
Status string
User string
}
Then we need some SQL code to read from the database. The code can be generalized and there are libraries that take away the boilderplate E.g. with a function that maps database result rows to a struct.
But in this example we write low level SQL code as a base level for comparison.
rows, err := pool.Query(context.Background(),
"select
t.id,t.title,u.name,s.status
from
tasks t, users u, status s
where t.user_id=$1
and t.user_id=u.id
and t.status_id=s.id"
, user)
if err != nil {
panic(err)
}
p := pgxbench.PgxTaskList{}
tasks := make([]pgxbench.PgxTask, 0)
for rows.Next() {
var id int64
var title string
var status string
var user string
err := rows.Scan(&id, &title, &user, &status)
if err != nil {
panic(err)
}
t := pgxbench.PgxTask{
Id: id,
Title: title,
User: user,
Status: status,
}
tasks = append(tasks, t)
}
p.Tasks = tasks
SQLX row mapping
One level above plain SQL is using a row mapper library like sqlx in Golang. The structs would be the same as with SQL but the boilerplate code is reduced to
err := db.Select(&tasks,
"select
t.id Id,t.title Title,u.name Name,s.status Status
from
tasks t, users u, status s
where
t.user_id=u.id and t.status_id=s.id and t.user_id=$1", user)
which is a reduction in code for most use cases. SQLX uses reflection for struct mapping which I assume will cost some performance. There are other libraries with a function as a row mapper, which have more code but better performance. Always those tradeoffs!
Gorm
GORM is an Object-Relational-Mapper (ORM) for Golang. An ORM translates method calls to SQL and puts data into a model. Using GORM we need a model:
type GormTaskList struct {
Tasks []Task
}
type User struct {
ID uint
Name string
}
type Status struct {
ID uint
Status string
}
type Task struct {
ID uint
Title string
UserID uint
User User
StatusID uint
Status Status
}
Then we can query the database with one line
db.Where("user_id = ?", userId).Preload("User").Preload("Status").Find(&tasks)
and hand it over to the template. We use Preload to load the dependent objects, otherwise we would need to load them later or when they are accessed. I assume this way we get the best performance.
There is a lot of magic going on and performance is hard to optimize or understand. I assume the magic will cost performance.
Generating JSON in Postgres
You can directly generate JSON in the database and then render it in a template.
With a small transformer that transforms $ and $$ to row_to_json, json_agg and json_build_object:
WITH tasks AS $(
SELECT
t.id id,
t.title title,
u.name name,
s.status status
FROM tasks t, users u, status s
WHERE t.user_id=u.id AND t.status_id=s.id
AND t.user_id=$1
)
$$(
'tasks', (SELECT * from tasks)
)
the Go code is just
row, err := pool.Query(
context.Background(),
query, args...)
if err != nil {
panic(err)
}
defer row.Close()
row.Next()
var json map[string]interface{}
if err := row.Scan(&json); err != nil {
panic(err)
}
return c.Render(http.StatusOK, template, json)
This code is the same for all handlers and can be reused. Only the query and template changes.
Reading Tasks with GraphQL
We use Graphjin as a server side Golang library to execute GraphQL against a Postgresql database. With GraphQL we only need one query:
query GetTasks {
tasks(where: { user_id: $userId } ){
id
title
user {
id
name
}
status {
id
status
}
}
}
The query returns JSON which we can directly feed into the template.
Performance
Caveat: I"m not a specialist in benchmarking Go. I’m also no specialist in pgx, sqlx, GORM or Graphjin. I’m not interested in faking a benchmark but in getting some insights. I’m thankful for any feedback on how to make code run faster or optimize configurations.
The benchmarks were run on WSL/Windows 11, Postgres 15, Go 1.19.3, Ryzen 3900x/12c, 32gb/3600, WD SN850 SSD.
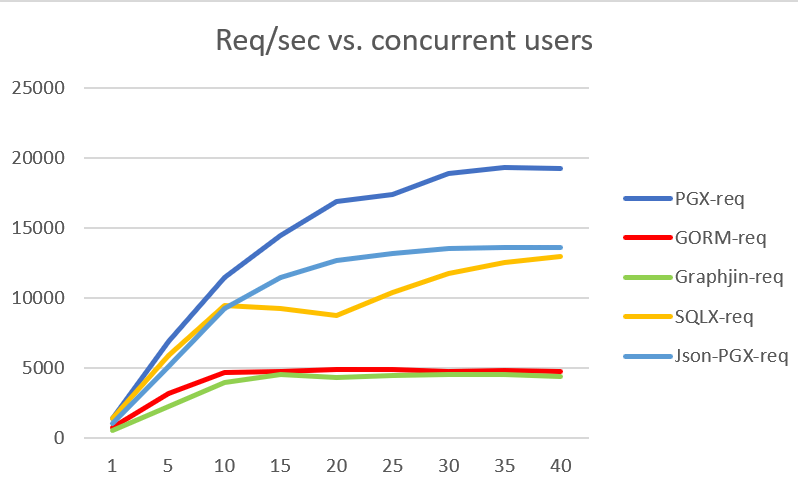
Looking at the performance of each of the solutions yields some surprises. The overall picture is no surprise, plain SQL is fastest, GraphQL is slowest and the SQLX mapper and the ORM in between. What is a surprise though is how much worse the mapper performs compared to handwritten SQL. The second surprise is how close the ORM and GraphQL is. I would have thought GraphQL was much worse in performance compared to an ORM.
The main drivers might be that GraphQL and the ORM create more objects and GC kicks in. Also the ORM and GraphQL create more or more complex queries. We might look into those in the future.
We use k6 to load test the application. All the pages do the same, load the tasks for one random user into memory and render it into HTML - in plain SQL, with SQLX, with GORM and with Graphjin. The DB is small but realistic for a small startup, 10000 tasks in the DB, 100 users, 100 task/user, 5 statuses. With indexes used I don’t think the size of the tasks table would have much of an impact.
(“concurrent users” == vu in k6)
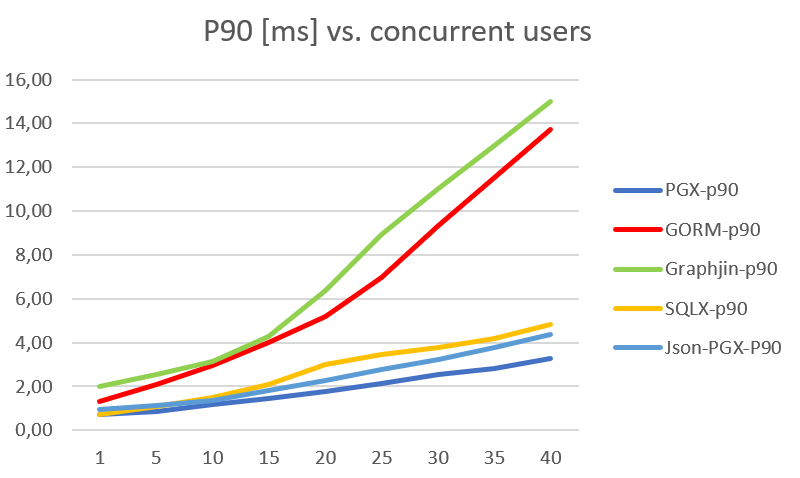
And the P90 ms it takes for one request
Comparison
The lines of code for the GraphQL solution is the smallest, you only need the query and no Go code. This makes adding an attribute to the view very easy: Add to the GraphQL query and add to the template. The ORM solution is next, with changes to the model and the HTML template and you’re done. The mapper needs changes to the struct and the SQL, the SQL solution needs changes to the query, the mapping and the struct. And all need changes to the HTML.
The GraphQL solution looks cleanest from the lines of code and the changes needed to add one new attribute.
There is a performance downside to GraphQL but it’s not as bad as I had assumed. If you’re already using an ORM, ignoring a read/write split, the ORM might be the best solution, but has a bigger performance impact than many people think. Plain SQL is fastest but needs the most changes and is harder to read and understand. The GraphQL and ORM performance is opaque though and harder to understand and optimize.
The biggest downside of GraphQL seems to be adding another dependency. Graphjin is no small package and has itself lots of third party dependencies. Another dependency is contraire to Radical Simplicity and therefor a tradeoff.
But for the speed of development and the easiness of change, while being still performant enough, I will consider GraphQL for my future projects of server side development.
About Stephan
As a CTO, Interim CTO, CTO Coach - and developer - Stephan has seen many technology departments in fast-growing startups. As a kid he taught himself coding in a department store around 1981 because he wanted to write video games. Stephan studied computer science with distributed systems and artificial intelligence at the University of Ulm. He also studied Philosophy. When the internet came to Germany in the 90 he worked as the first coder in several startups. He has founded a VC funded startup, worked in VC funded, fast growing startups with architecture, processes and growth challenges, worked as a manager for ImmoScout and as a CTO of an eBay Inc. company. After his wife successfully sold her startup they moved to the sea and Stephan took up CTO coaching. You can find him on LinkedIn, on Mastodon or on Twitter @KingOfCoders